Design og UX / 6 minutter /
Seks viktige ting å tenke på når du jobber med kunstig intelligens
Du husker sikkert kanskje debatten om Sporveiens julekampanje før jul hvor de hadde brukt KI-genererte bilder. Resultatet var en julenisse med seks fingre og at han holdt på å dytte bestemor foran trikken. Velkommen til en verden med kunstig intelligens! Dette vil endre måten vi jobber med brukeropplevelse på.


Hva var det som skjedde i Sporveiskampanjen? Først må vi forstå hvordan kunstig intelligens (KI) og maskinlæring fungerer. Maskinlæring er en del av KI-universet og det er stort sett maskinlæring denne artikkelen handler om.
I klassisk programmering er det vi som lager reglene og på den måten styrer hvilke svar vi får.

I maskinlæring mater vi inn data og svar og så er det kunstig intelligens som lager reglene. Resultatet er at vi får systemer som kan analysere store mengder data raskt og finne sammenhenger vi ikke kan se. De kan også lære av erfaring. Dette er kjempenyttig innenfor mange områder. Det gir oss også muligheter vi ikke hadde før, som for eksempel språkmodellen ChatGPT og bildegenerering som Sporveien brukte.
Maskinlæring kan deles opp i 3 hovedkategorier:
- Veiledet læring: maskinen får hjelp av eksempler vi gir den
- Ikke-veiledet læring: maskinen grupper dataene selv (klyngeanalyser) og kan lage anbefalingssystemer (f.eks Netflix)
- Forsterket læring: maskinen får tilbakemelding på om den har predikert riktig eller feil
Maskinlæringsmodeller er basert på statistikk og sannsynlighet. Den har blitt veldig flink, men den er ikke smart. I tillegg er kvaliteten på maskinlæringsmodellen helt avhengig av dataene som blir brukt for å trene den. Her gjelder «Shit in - shit out». Bruker vi riktige og gode data når vi trener modellen?

...maskinlæringsmodellen har blitt veldig flink, men den er ikke smart.
Alt dette er vanskelig for folk flest å forstå og det påvirker de som skal bruke dem. Nå skal jeg gå gjennom seks eksempler på hvorfor det er viktig å ha fokus på brukeren når vi jobber i prosjekter med maskinlæring.
1. Brukerbehov
Det første vi må jobbe med er hva er problemet vi skal løse og hvordan skal vi løse det? Kartlegg brukerbehov, - adferd og problemer for å finne brukerens «pains and gains». Deretter må dere vurdere om maskinlæring skaper unik verdi for å løse brukerens problem - eller er det bare noe vi har lyst til å gjøre? Finn krysningspunktet mellom brukerbehovene og styrkene til maskinlæring.
En annen ting dere må vurdere er om løsningen skal automatisere eller være et støtteverktøy. Finn ut hvilke oppgaver brukeren liker å gjøre selv og hva de synes er kjedelig og tidkrevende.
Finn ut hvilke oppgaver brukeren liker å gjøre selv og hva de synes er kjedelig og tidkrevende
Oppgaver som er tidkrevende og kjedelige kan automatiseres. Hvis brukeren liker oppgaven og vil gjøre den selv, lag et maskinlæringssystem som fungerer som et støtteverktøy. Det kan også være lurt å bruke maskinlæring som et støtteverktøy om man ikke er 100 % enig om hva som er den riktige måten å løse en oppgave på.
Vurder konsekvensene av ulike prediksjoner maskinlæringsmodellen kan gjøre og design gode tilbakemeldingsmekanismer. Bruk disse til å forstå hvor godt dere løser problemet med maskinlæringsmodellen. Tilbakemeldinger er ofte bare symptomer på et problem og bør hypotesetestes slik at man finner det egentlige problemet. Dette er noe teamet må gjøre sammen.
2. Mentale modeller
En mental modell er en persons forståelse for hvordan maskinlæringsmodellen virker og hvordan egen aktivitet kan påvirke det. Hvilke forventninger har brukerne til maskinlæringsmodeller sammenlignet med tradisjonell programmering? Har de i det hele tatt en mental modell av det tekniske? Brukere kan ha andre mentale modeller og ulike behov for hvordan problemet bør løses. Identifiser eksisterende mentale modeller relatert til problemet som skal løses og bygg på dem.
Tradisjonelt er de fleste produkter statiske, de oppfører seg likt hver gang. Med maskinlæringsmodeller vil man oppleve at produkter endres over tid fordi den lærer og utvikler seg basert på hvordan den brukes. Derfor er det viktig å lage en felles plan for læring, både for systemet og brukeren.
Skap realistiske forventninger til løsningen. Vær tydelig på hva produktet kan og ikke kan gjøre og hvordan egen aktivitet forbedrer løsningen. Forklar fordelene med systemet, ikke teknologien.
3. Tillit
For å ha tillit til løsningen må man være sikker på at man får jobben gjort, at man kan stole på resultatet og at systemet “vil meg vel”. Det kan være vanskelig å forklare hva systemet gjør. Forklar derfor det viktigste og i riktig kontekst. Bruk trinnvis onboarding og introduser ny funksjonalitet når det er behov for det.
Maskinlæringsmodeller kan predikere feil. Brukeren må få hjelp til å vite når de kan stole på systemet og når må de gjøre egne vurderinger. Hvor sikkert systemet oppleves, påvirker beslutninger brukeren tar. Ved å brukerteste tilliten til løsningen kan du enklere lage løsninger som skaper tillit.
Vær åpen om hvilke data som samles inn og hva de brukes til. Transparens i løsninger som bruker maskinlæring er ikke bare et spørsmål om å forklare hvordan modellen fungerer, datakilder, vilkår og output. Det er også en grunnleggende komponent for å oppnå tillit. For å ivareta dette er det viktig at tjenesten merker resultatene med at de er KI-genererte. Vi ser allerede dette i bruk i for eksempel NRK og VG som bruker KI til å oppsummere nyhetssaker. De informerer om at teksten er generert av ChatGPT. Dette bidrar til legitimitet og ufarliggjøring av KI.
4. Datainnsamling
Treningsdata refererer til datasettene som brukes til å trene en maskinlæringsmodell. Disse dataene utgjør grunnlaget for at modellen skal kunne lære og forbedre seg. Treningsdataene inneholder vanligvis input (data) og tilhørende output (svar) som modellen skal lære av. Kvaliteten på modellen er avhengig av dataene den trener på. Hvilke data trenger du for å møte brukerens behov? Hvordan ble dataene samlet inn og hvordan er de transformert?
I veiledet læring blir ofte treningsdataene labelet (tag´et) av mennesker. Det sitter altså mennesker (ofte dårlig betalt) og manuelt tagger dataene med informasjon. Hvilke instrukser de som labeler dataene har fått og hvor brukervennlig løsningen de bruker er påvirker kvaliteten i dataene. Hvordan er det lagt til rette for å unngå feil og bias i disse dataene?
Når modellen er testet på treningsdataene må vi evaluere hvorvidt modellen møter suksesskriteriene vi har satt. Vi må justere modellen kontinuerlig basert på tilbakemeldinger og feedback. Samtidig må vi sjekke om datakvaliteten er god nok, om vi har riktige data eller om vi har nok data for å løse for å løse problemstillingen og brukerbehovene.
5. Feedback
Feedback er selve kjernen i maskinlæring, spesielt i forsterket læring (f.eks fysiske roboter eller selvkjørende kjøretøy). ChatGPT bruker også dette hvor brukere kan gi tommel opp/ned på et svar, som så brukes til å forbedre modellen.
Her får vi en ny utfordring i form av å samle inn relevant feedback uten at brukeropplevelsen reduseres. Dette er feedback som ikke er vanlig i tradisjonell programmering og som kan oppleves som irriterende og forstyrrende i brukerens arbeidsflyt.
Du kan samle feedback implisitt ved logging eller eksplisitt ved å be brukeren gjøre valg. Skaff innsikt i hvilke data brukerne synes det er greit å logge og hvilke data brukeren selv vil ha kontroll på at de gir fra seg. Balanser mellom automasjon og kontroll, og gi dem mulighet til å endre eller avstå fra å gi tilbakemelding.
For å sikre en god brukeropplevelse rundt tilbakemeldingsfunksjonen (slik at de faktisk gir feedback) er det også viktig å forstå hvorfor brukerne velger å gi feedback. Er det materielle eller symbolske årsaker? Vil det gi brukeren personlig nytte, er det altruisme eller indre motivasjon. Design og brukertest tilbakemeldingsfunksjonen slik at det gir verdi for brukeren.
6. Feilhåndtering
Fordi maskinlæring er basert på statistikk og sannsynlighet, vil den kunne predikere feil. Definer mulige feil og svakheter og vurder hvordan det påvirker brukervennligheten, tillit og mentale modeller.
I tradisjonell produktutvikling har vi forholdt oss til to typer feil. Vi har fanget opp brukerfeil og forbedret løsningen for å unngå at det skjer igjen. Vi har fanget opp systemfeil og rettet på dem i koden. Når vi skal jobbe med maskinlæringsmodeller dukker det opp nye typer feil. Det er ikke alle disse feilene som er så lette å fikse:
Faktiske feil skjer fordi maskinlæringsmodellene er flinke, men ikke smarte. I språkmodeller som ChatGPT beregner den sannsynligheten for neste ord basert på dataene den har tilgjengelig, den vet ikke om det er riktig. Når svaret på spørsmålet den får ikke finnes i dataene, vil den likevel produsere et svar basert på sannsynlighet i dataene. Det kan resultere i at den “lyver”. Det samme gjelder for bildegenerering og kan forklare hvorfor julenissen fikk seks fingre og ser ut til å ta livet av bestemødre med et smil.
Kontekstfeil er feil som skjer når prediksjonene til maskinlæringsmodellen ikke stemmer med brukerens kontekst der og da. Et eksempel på dette er bildet under, som maskinlæringsmodellen har laget av laks som svømmer nedover en elv.
Villaks, salmalaks, lakseloin, laksefilet – det er altså samesame for maskinlæringsmodellen. For husk, den er flink, ikke smart 😉:

Kontekstfeil kan være sanne positive, men de bryter likevel med brukerens mentale modell. For å unngå kontekstfeil må vi undersøke hvilke antagelser maskinlæringsmodellen brukte for å sette brukerens kontekst.
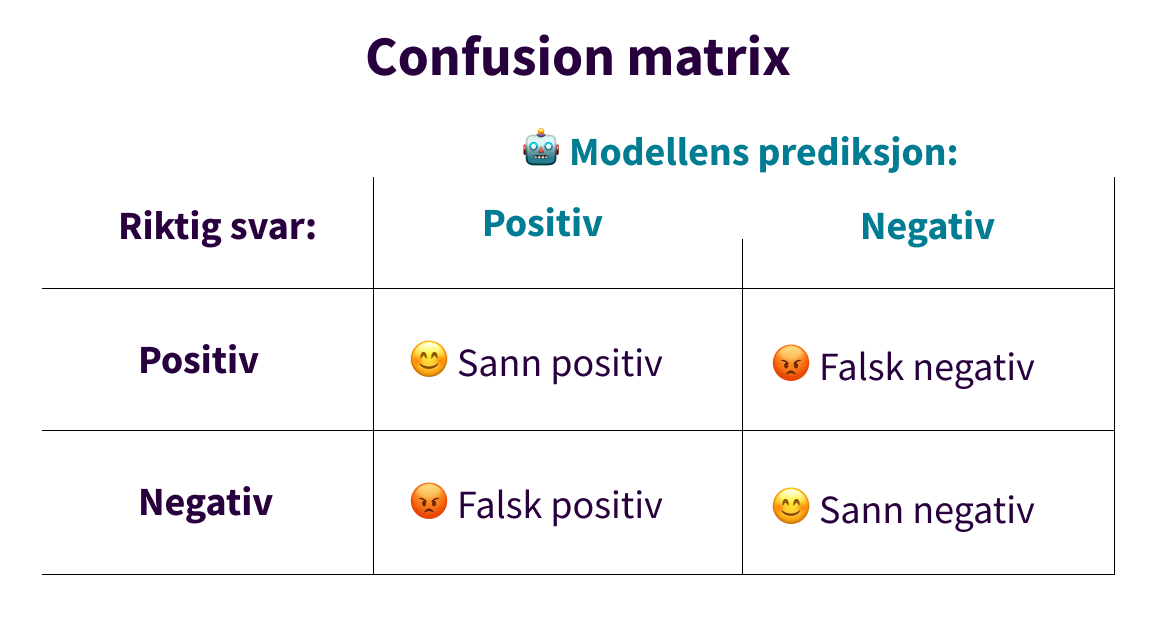
Confusion matrix er en feilmatrise som illustrerer ytelsen til maskinlæringsmodellen. Hvis modellen predikerer det som er riktig har vi enten sanne positive eller sanne negative. Dette gir gode brukeropplevelser fordi løsningen gir riktig svar. Feilmatrisen hjelper oss å forstå andre typer feil maskinlæringsmodellen kan gi. Den kan predikere feil i form av falske negative, for eksempel ved at man ikke oppdager kreft på et bilde. Eller man får falske positive ved at man ikke får brukt kredittkortet sitt fordi systemet predikerer at det er svindel. Dette gir dårlige brukeropplevelser og må håndteres på en god måte.
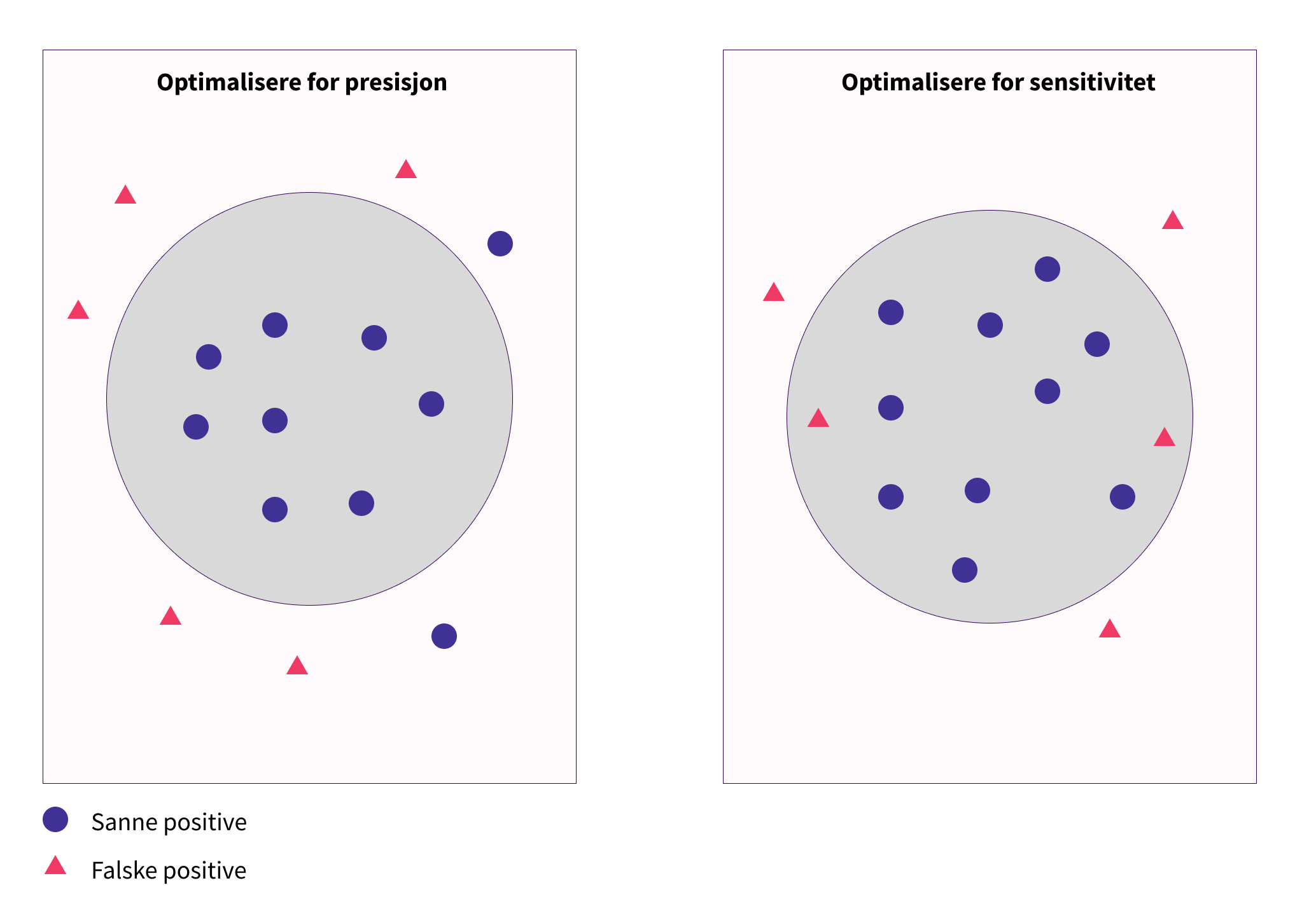
Sannsynligheten for slike feil vil avhenge av modellens presisjon (andel korrekt informasjon) og sensitivitet (andel relevant informasjon). Hvis vi velger høy presisjon vil vi ha lavere sannsynlighet for feil, samtidig som vi risikerer å gå glipp av relevant informasjon (sanne positive). Hvis vi fokuserer på høy sensitivitet er det høy sannsynlighet for å fange opp alle sanne positive, men vi risikerer å få feil (falske positive). Det er viktig å finne balansen mellom presisjon og sensitivitet.
Alle disse feilene må håndteres på en brukervennlig måte slik at brukeren forstår hva som skjer og kan gi feedback slik at vi kan lære og forbedre løsningen. Vi må også sikre at de får en vei videre. God feilhåndtering kan være utfordrende når vi ikke vet hvilken feil som oppstår. Hvis vi gjør dette på en god måte vil vi øke brukeropplevelsen og tilliten til løsningen.
Samarbeid ML og UX
Maskinlæringsmodeller krever tettere samarbeid mellom designere og utviklere, spesielt de som skal utvikle og trene modellen. Designeren vil ha domenekunnskap om brukerbehov og -adferd som utviklerne kanskje ikke sitter på. Det er en klar fordel for prosjektet å ha med domenekunnskapen tidlig i prosjektet og ikke oppdage eventuelle svakheter etter at modellen er laget.
Utviklere og designere må samarbeide for å sikre at modellen løser det riktige problemet, håndterer feil på en god måte og sikrer gode tilbakemeldingsmekanismer.
Det er også viktig å ha med designere i arbeidet med treningsdata. Dataspesifikasjonen må defineres av problemstillingen og datasettet må reflektere hele målgruppen. Den må også inneholde relevant funksjonalitet/variabler og labels i forhold til oppgavene som skal løses av modellen. Domenekunnskapen designerne har er viktig å ha med i denne prosessen for at treningsdataene skal bli gode.
For å få til dette samarbeidet må designere øke sin kunnskap om maskinlæring. De må også sørge for at de blir inkludert tidlig i prosessen når det skal utvikles maskinlæringsmodeller. De må synliggjøre sin kompetanse og hvordan de kan skape verdi.
Maskinlæring er et relativt nytt fagfelt med store konsekvenser for de som skal bruke løsningene. Utviklere trenger å øke sin kompetanse på designthinking slik at de har økt fokus på- og involverer brukerne gjennom hele prosessen.
Lyst til å lære mer?
People + AI Guidebook» https://pair.withgoogle.com/guidebook/
AI meets Design toolkit: https://aixdesign.co/
Designprisnipper for AI: https://uxofai.com/
Anta bias. Alltid: https://www.kantega.no/blogg/anta-bias-alltid
UX challenges for AI/ML products:
- Trust & Transparency https://medium.com/aixdesign/ux-challenges-for-ai-ml-products-1-3-trust-transparency-31df88c6f827
- User feedback and control https://medium.com/aixdesign/ux-challenges-for-ai-ml-products-2-3-user-feedback-control-6a620d19faf0
- Value alignment https://medium.com/aixdesign/ux-challenges-for-ai-ml-products-3-3-value-alignment-e0b6b22ad9
Eller å ta kurset «Design-tenkning og kunstig intelligens» på NTNU, slik jeg gjorde.