Teknologi / 4 minutter /
RAG: En effektiv måte å komme i gang med generativ AI basert på egne data
RAG, eller Retrieval-Augmented-Generation, lar deg utnytte store språkmodeller som GPT-4 ved å berike og avgrense modellen til et kvalitetssikret kunnskapsgrunnlag. Med dette begrenser man sannsynligheten for hallusinasjoner og utdaterte svar. Kostnadseffektivt er det også.

Illustrasjon generert av Stable Diffusion / Diffusion Bee

RAG — kjapt forklart
RAG, er en prosess der output fra en stor språkmodell tilpasses informasjon som ikke nødvendigvis var del i trening av den opprinnelige modellen. Kapabilitetene fra store, generelle språkmodeller kombineres med kontekstberiking og tilpasning av respons på en kostnadseffektiv måte.
En RAG-løsning lar deg ‘snakke med’ data, og kan for eksempel presenteres som spørsmål- og svartjenester, domeneeksperter eller personaliserte chatbots.
Figuren under viser et eksempel på hvordan en enkel RAG-løsning kan settes opp.
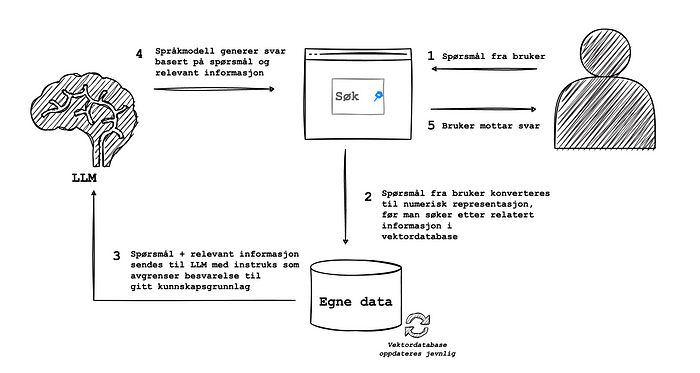
RAG-løsning i korte trekk
I eksempelet har vi en spørsmål- og svartjeneste som skal dra nytte av egne data. Vi trenger i utgangspunktet kun 3 enkle elementer:
- En vektordatabase som inneholder numerisk representasjon av et oppdatert og kvalitetssikret kunnskapsgrunnlag. Dette er tegnet inn som ‘egne data’.
- Tilgang til en stor språkmodell
- Et brukergrensesnitt
I denne løsningen starter vi med å ta input fra en bruker (1). Denne inputen konverteres deretter til et format som gjør det mulig å lete etter relatert informasjon, uten å kreve for eksempel ordlikhet (2). Dette gjøres typisk ved å beregne en form for avstand, som cosinuslikhet, mellom den numeriske representasjonen av spørsmålet og av tekstutdrag i kunnskapsdatabasen.
Deretter kombineres det opprinnelige spørsmålet med relevant informasjon, og sendes til en stor, generell språkmodell (3). Ved gode instrukser, eller prompts, vil man da kunne peke modellen i retning gode svar, avgrenset til aktuell kontekst gitt av treff i kunnskapsdatabasen.
Svaret fra språkmodellen sendes deretter tilbake til brukeren (3–4).
I mange RAG-løsninger vil man også legge på mellomsteg som for eksempel søker i (pregenererte) oppsummeringer, formaterer output og sjekker eller reformulerer input.

En oppdatert og kvalitetssikret kunnskapsdatabase er gullet i god RAG-løsning. Bilde generert med Stable Diffusion / Diffusion Bee
Kunnskapsdatabasen må oppdateres jevnlig, og være kvalitetssikret for feil. Det er denne som virkelig er ‘gullet’ i løsningen — og som vil representere noe ingen generell språkmodell vil kunne tilby ut av boksen.
Hvorfor er RAG nyttig akkurat nå?
Bruk av store, generelle språkmodeller, som ChatGPT, innebærer en del kjente utfordringer. Blant annet vil modellene kunne gi uriktig informasjon når svaret ikke er kjent, og svare basert på utdatert informasjon eller upresise kilder. Dette skyldes blant annet at store språkmodeller er basert på enorme treningsdatasett som umulig kan inspiseres og kvalitetssikres manuelt.
I stedet for å ta i bruk RAG, kunne mange av disse utfordringene vært løst ved å dumpe en komplett kunnskapsdatabase direkte til store språkmodeller, og be modellen svare på bakgrunn av dette. Hovedutfordringen med denne tilnærmingen, er at selv de mest kraftfulle modellene, som OpenAIs GPT-4, har begrensinger når det gjelder hvor mye kontekst man kan gi i en enkel prompt.
RAG er et forsøk på å jobbe rundt denne begrensningen, og gir samtidig flere store fordeler målt mot direkte bruk av store språkmodeller og enkel prompt engineering.
Mindre hallusinasjoner
En av de virkerlig store fordelene med RAG er at vi begrenser sannsynligheten for hallusinasjoner.
Ved å kombinere gode eksempler, tydelig instruksjon, og en kvalitetssikret og avgrenset kontekst, blir sannsynligheten for at modellen gir uriktig eller utdatert informasjon langt lavere. Ved god prompt engineering sørger vi også for at modellen ikke forsøker å svare på spørsmål utenfor konteksten den gis.
Det er verdt å nevne at RAG-teknikk ikke er en 100% sikker metode som sikrer at modellen holder seg innenfor relevant kontekst. Gjennom såkalt ‘jailbreaking’ vil det fortsatt være mulig å få modellen til å gi uønsket output. Dette er en utfordring vi har sett utallige eksempler på — men som ikke nødvendigvis er et godt argument for å la være å utvikle løsninger som ellers gir gode svar.
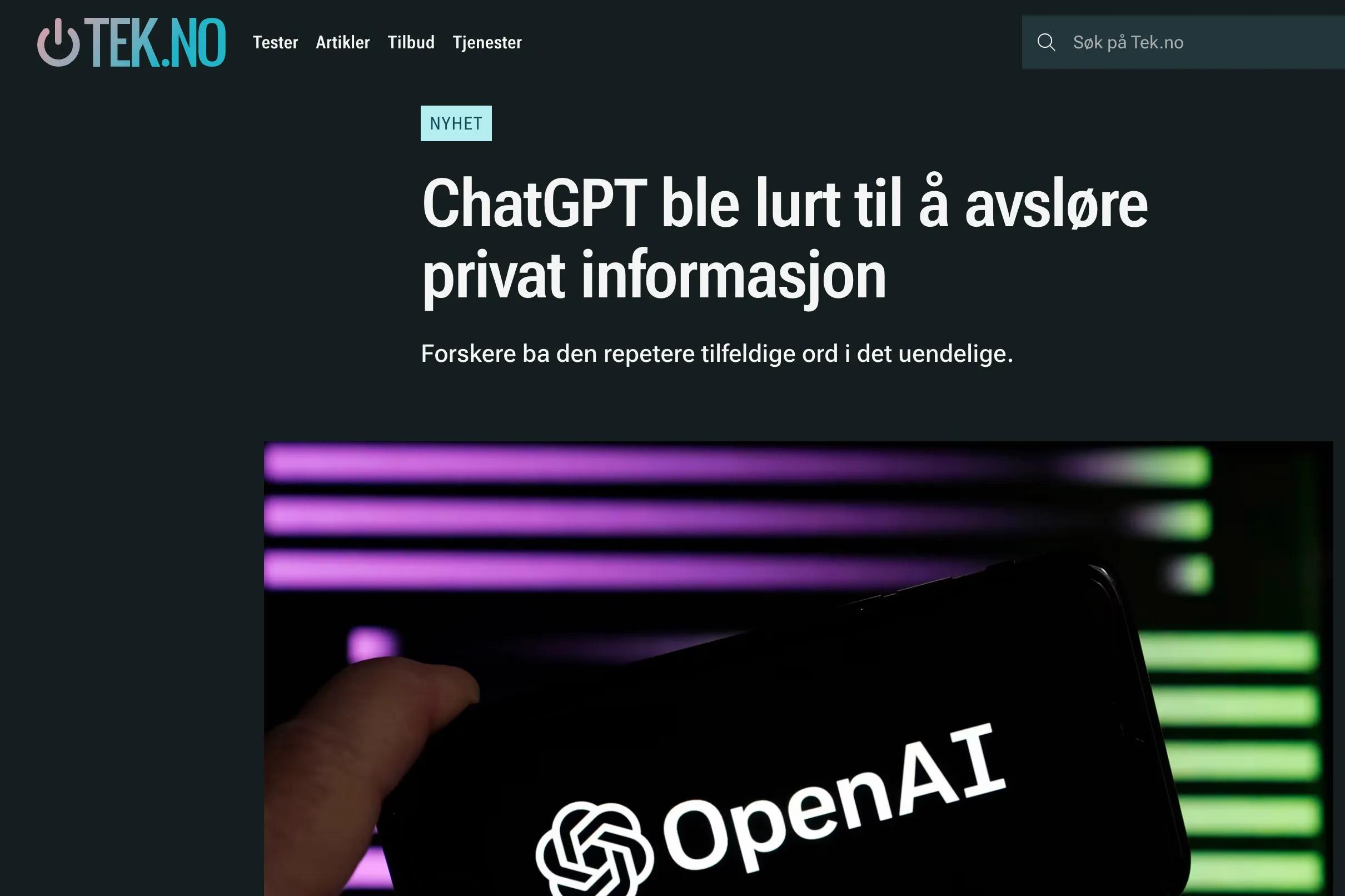
RAG vil ikke være en 100% sikker måte å unngå uønsket output. Skjermdump fra tek.no
Dette må vurderes også med hensyn til antatt verdi, risiko, tillit til brukergruppen og forventing til løsningen. Kanskje vil virkelig gode svar i 95% av tilfellene fortsatt gi mer enn god nok verdi.
Berike kunnskapsgrunnlaget (med egne data)
Med RAG har du mulighet til å gjøre en stor språkmodell kjent med informasjon som ikke var tilgjengelig for modellen da den i utgangspunktet ble trent. Dette er spesielt nyttig hvis du drar nytte av egne, og gjerne proprietære, data. Kanskje kan du tilby egen kunnskapsdatabase som et produkt på en langt mer effektiv måte, ved å la brukere ‘snakke med’ innholdet, i stedet for å gjøre manuelle søk.
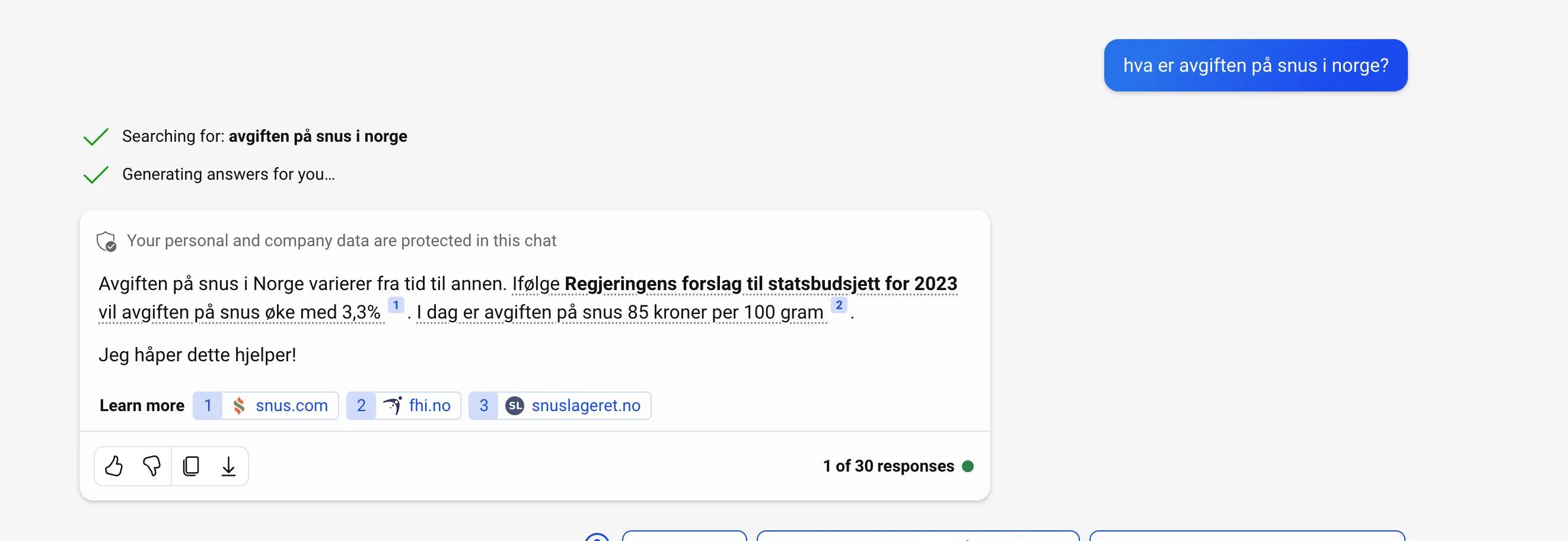
Et greit svar fra bing basert på store språkmodeller. Problemet er at informasjonen er utdatert. Dagens avgift er egentlig 97 kr/100 gram. Skjermdump fra bing.com 24.01.24
Vi har allerede begynt å bli fortrolig med denne måten å hente informasjon på, for eksempel gjennom AI-baserte søketjenester. Hovedutfordringen med disse generelle søkene, er igjen at kunnskapsgrunnlaget ikke er godt nok kvalitetssikret og avgrenset, og det er enkelt å blande sammen data på en uheldig måte som genererer dårlige svar. På egne data har man langt større kontroll, og man trenger ikke nødvendigvis å begrense seg til åpne kilder.
Kostnadseffektivt
RAG er en kostnadseffektiv måte å komme i gang med generativ AI på. Store, generelle språkmodeller er trent på enorme, generelle datasett. Retrening av slike modeller for domenespesifikk bruk kan være svært kostbart målt mot bruken av RAG-teknikker, selv om såkalt fintrening også har sine fordeler (det er ikke umulig at det kommer en bloggpost om dette senere).
Ta kontakt om du er interessert i å utforske RAG-løsninger på egne data, vi deler gjerne våre erfaringer.





