Teknologi / 7 minutter /
Avanserte maskinlærekonsepter: Autoenkoderen
I denne serien med artikler skal vi utforske forskjellige maskinlæremodeller, arkitekturer og konsepter som kanskje vil være nye for selv en med litt “Data Science” erfaring.
Det forventes at leseren har en viss grunnleggende forståelse for maskinlæring og spesielt dyplæring, men har man ikke dette kan det kanskje være litt spennende likevel ☺️
Github-link til kodeeksempelet i denne bloggen her.

Del 1: Autoenkoderen
Det første som er lurt å spørre seg når man skal lære noe nytt er hvorfor.
“Hvorfor skal vi lære om autoenkodere”?
Hvis svaret virker interessant kan man deretter stille spørsmålene hva er det? Og hvordan fungerer det?
I denne posten skal vi se på autoenkodere og prøve å besvare akkurat disse spørsmålene.
Hvorfor autoenkoder?
Autoenkodere er en type unsupervised machine learning model. Med andre ord et nevralt nettverk som ikke lærer seg å gjenkjenne hva inputen er, men heller forsøker å lære noe interessant om de underliggende mønstrene i dataen.
Denne kunnskapen kan deretter brukes til å løse forskjellige problemer, f.eks:
- Anomalideteksjon, f.eks gjenkjenne at noe virker unormalt med utstyret på et romfartøy [1]
- Denoising, f.eks fjerne støy fra medisinske bilder [2]
- Bilde-rekonstruksjon [3]
- Datakomprimering og dekomprimering (lossy)[4]
Hvis problemene man ønsker å løse ligner på noen av disse, kan en autoenkoder kanskje være løsningen.
Hva er en autoenkoder?
En autoenkoder er en maskinlæremodell som lærer å kopiere dataene den tar inn. Dette i seg selv er ikke noen storslått egenskap, og det finnes andre måter å gjøre dette mye mer effektivt på enn å bruke et nevralt nettverk.
Men selve poenget med en autoenkoder er ikke å kopiere dataene, dette er, som man kan si, a means to an end.
Målet med en autoenkoder er å la det nevrale nettverket lære seg mønstre og underliggende sannheter om dataene den kopierer
For eksempel, gitt et ønske om å trene et nettverk til å komprimere og dekomprimere data. Da er vi avhengig av at modellen har en forståelse for hva det er i dataene den komprimerer som er viktig for senere å kunne dekomprimere den.
For å lære seg å selektere den viktigste informasjon må vi innføre restriksjoner på hvordan nettverket får lov å gjennomføre kopieringen. Den mest kjente måten å gjøre dette på er å redusere hvor mye av den originale inputen modellen får lov å ta vare når den propagerer dataene gjennom nettverket. Ved å innføre slike restriksjoner tvinger man nettverket til kun å prioritere den viktigste informasjonen. Med andre ord må modellen filtrere ut irrelevante data og kun ta vare på informasjon som er viktig for å rekonstruere originalen. Det er denne evnen til å kun selektere det viktigste i inputen og ignorere alt annet, som gir en autoenkoder kreftene sine.
I neste avsnitt skal vi leke oss litt med et eksempel på hvordan en veldig enkel autoenkoder kan lære seg å komprimere og dekomprimere håndskrevne tall fra MNIST datasettet [5].

Eksempler fra MNIST datasettet
Hvordan fungerer autoenkoderen?
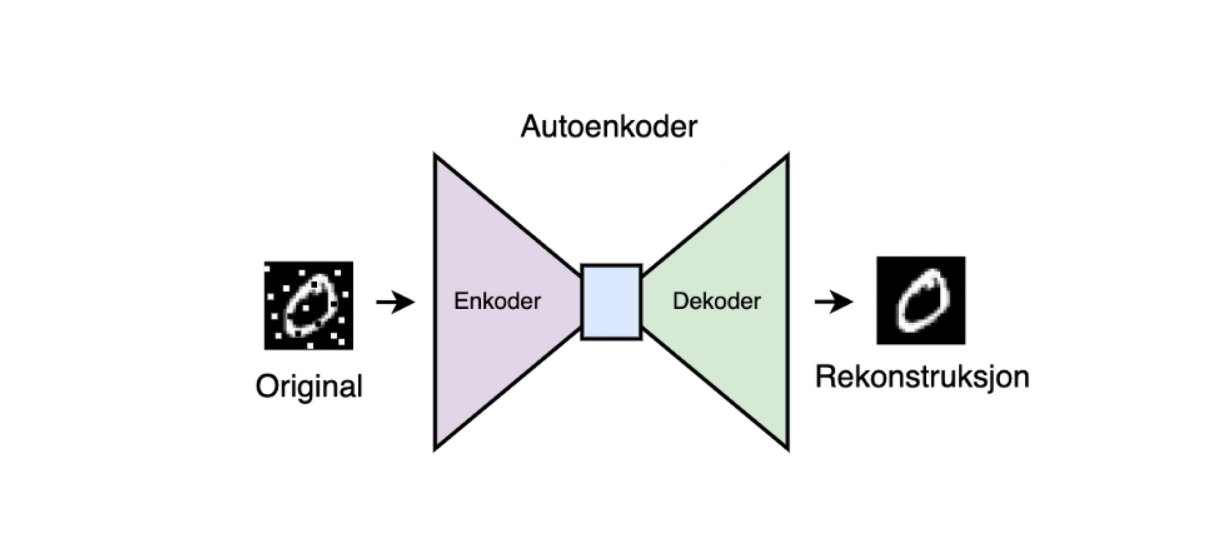
Figur 2: En enkel autoenkoder
I figuren over kan man se en veldig enkel illustrasjon av autoenkoderen vi skal bygge i løpet av de kommende seksjonene.
Enkoder
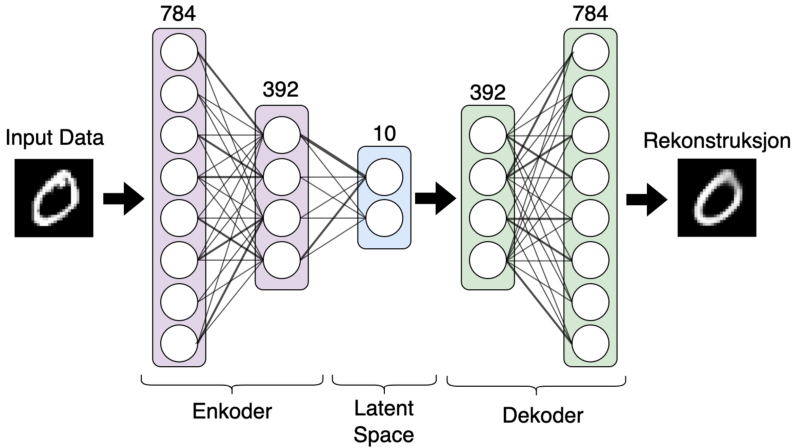
Enkoderen er den delen av nettverket som står for å komprimere dataene nettverket tar inn. I Figur 1 kan enkoder sees som de lilla og blå lagene i nettverket. Det ytterste laget i nettverket(helt til venstre) består av 784 nevroner, en nevron pr. pixel i inputdataene. Ettersom vi beveger oss innover i dypet av enkoderen ser vi at det blir færre og færre nevroner pr. lag der vi til slutt ender opp med et lag bestående av kun 10 nevroner. Dette er det siste laget i i enkoderen, og det er her man finner det som ofte kalles the latent representation in latent space. Dette er bare en fancy måte å si nettverkets indre representasjonen av inputdataene. I vårt tilfelle vil outputen fra enkoderen kun bestå av 10 flyttall, en komprimert versjon av bildet det tar inn som består av 784 flyttall.
I figuren under kan man se hvordan man kan lage en enkel enkoder ved å bruke tensorflow.
I kodesnippeten oppretter vi en enkoder bestående av 4 lag. Det første laget er kun brukt til å flate ut inputen siden vi bruker dense-layers som lag i nettverket. Vi bruker Dense layers i nettverket, der hvert nevron i et lag er koblet til alle nevroner i det neste laget. Dette er ikke nødvendigvis den beste typen lag for autoenkodere som tar bilder som input, men fungerer greit nok i dette leke-eksempelet.
NB! Husk at Dense Neural Networks (DNN), kun takler 1-dimensionell input.
Dekoder
Dekoderen kan sees på som en speilvendt versjon av enkoderen. Det er vanlig å bruke den samme lag-strukturen som enkoderen har, men i revers. Her blir dataen rekonstruert fra lag til lag gjennom nettverket, og dette kun fra den komprimerte, indre representasjonen dekoderen mottok fra enkoderen.
I kodesnippeten over ser vi at dekoderen består av de samme lagene som enkoderen, i revers, og til slutt reshaper vi outputen tilbake til original-formatet til inputen.
Autoenkoder
Autoenkoderen bygges enkelt og greit ved å sette i sammen enkoderen og dekoderen.
Trening
I et typisk klassifiseringsproblem der vi har et datasett bestående av treningsdata og labels trener man nettverket ved å måle forskjellen mellom labelen nettverket tror er riktig for en gitt sample og den faktiske labelen ved å bruke en loss-function. Deretter bruker man resultatet fra denne funksjonen til å oppdatere vektene i nettverket slik at distansen mellom riktig og predikert label reduseres.
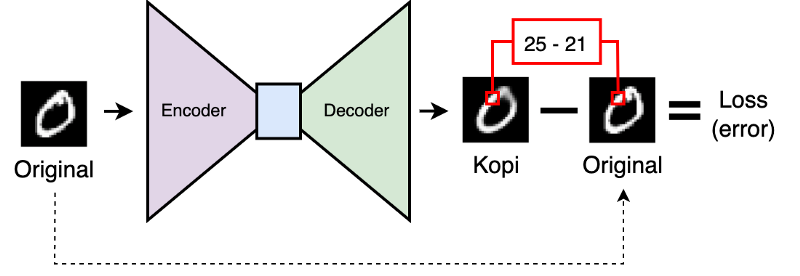
Figur 3: Forenklet illustrasjon av loss kalkulasjon for en autoenkoder
Autoenkodere trenes på samme måte som nevrale nettverk ellers, vi måler hvor feil nettverket tar og justerer vektene for å redusere denne feilen. Forskjellen ligger i hvordan vi måler feilen.
For å måle hvor bra en autoenkoder gjør jobben sin bruker vi ikke forhåndsmerkede data, men vi sammenligner i stedet outputen til nettverket med inputen. Dette kan for eksempel gjøres med mean squared error loss funksjonen, der vi enkelt og greit beregner hvor stor forskjell det er mellom hver enkelt pixel i input og output, summerer og deler på antallet pixler.
I snippeten over kompilerer vi autoenkoder modellen vår med mean squarer error som loss funksjon og ADAM[6] som optimizer, for så å trene nettverket på et utdrag data fra MNIST.
NB! Hva X_train består av og hvordan denne arrayen opprettes kan sees både i github repoet vårt her, men vil også forklares til slutt i artikkelen.
Resultat
I motsetning til en klassifseringsmodel der målet er å oppnå en nøyaktighet så nær 100% som mulig, er ikke dette nødvendigvis en bra målestokk for hvor bra en autoenkoder gjør jobben sin.
Hvis autoenkoderen ikke har noen restriksjoner, og nettverket er stort, vil det ganske raskt klare å oppnå en veldig høy kopieringsnøyaktighet.
Det er derfor viktig når man skal vurdere modellen å ta med i betraktingen hva man ønsker å oppnå med autoenkoderen. F.eks. i vårt tilfelle var det å lage en “komprimeringsalgoritme”. Med denne målsettingen må vi i tillegg til modellens nøyaktighet ta hensyn til modellens komprimeringsevne. Med andre ord hvor mye klarer vi å “krympe” inputen mens vi fortsatt klarer å rekonstruere originalen.
I figuren under ser vi et utdrag tall fra MNIST datasettet, disse tallene tilhører et “valideringssett” modellen vår aldri har sett før. Vi ser også hvordan tallene ser ut etter at modellen vår først har komprimert tallene, (mao. redusert størrelsen på inputen 78 ganger). For så å rekonstruere dem igjen.
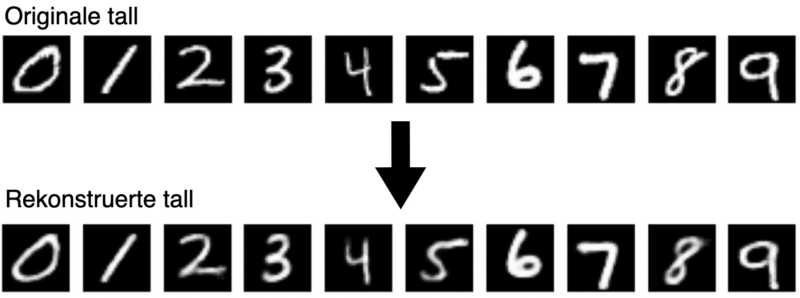
Figur 4: Sammenligning av originale og reoknstruerte tall
Treningsoppsett
Denne seksjonen inneholder ikke noe spesifikt for autoenkodere, men gir en rask forklaring av resten av koden i notebooken.
Først bruker vi sklearn sin fetch_openml funksjon for å laste MNIST datasettet inn i minnet. Deretter henter vi ut bildene og konverterer disse til 28x28 format, for så å hente ut labels for alle bildene (NB! Labels brukes kun til visualisering og ikke i selve treningsprosessen)
Deretter deler vi MNIST opp i trenings- og valideringsset, shuffler bildene og til slutt normaliserer pixlene til en verdi mellom 0 og 1. X_train vil da inneholde 80% av alle bildene i datasettet, der pixlene er normalisert.
Potensielle forbedringer og videre arbeid
I eksempelet vi har jobbet oss igjennom bruker vi bla. en autoenkoder bestående av dense layers til å komprimere og dekomprimere 2D-bilder. Et naturlig forslag til de som ønsker å eksperimentere med dette på egen hånd er å bytte ut lagene med convolutional layers. Man kan også forsøke å komprimere dataene enda mer ved å optimalisere modellen i notebooken.
Referanser:
[1]: Mayu Sakurada and Takehisa Yairi. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd workshop on machine learning for sensory data analysis, pages 4–11, 2014.
[2]: Gondara, Lovedeep. “Medical image denoising using convolutional denoising autoencoders.” 2016 IEEE 16th international conference on data mining workshops (ICDMW). IEEE, 2016.
[3]: Zheng, Jin, and Lihui Peng. “An autoencoder-based image reconstruction for electrical capacitance tomography.” IEEE Sensors Journal 18.13 (2018): 5464–5474.
[4]: Liu, Tong, et al. “High-ratio lossy compression: Exploring the autoencoder to compress scientific data.” IEEE Transactions on Big Data (2021).
[5]: https://www.openml.org/search?type=data&sort=runs&id=554&status=active
[6]: Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).





